I built typwrtr, and my dictation got better(and free)
A new category of voice dictation is emerging: local-first, GPU-accelerated, and actually learns from your edits. typwrtr runs entirely on your machine, improves after every correction, and never sends your audio or text to the cloud.
How I built typwrtr — a local-first voice dictation tool that learns from your edits, runs on your GPU, and never sends a byte to anyone's cloud.
The unmet category
If you want to type with your voice in 2026, you have two real options.
You can pay Wispr Flow $144 a year ($12/month annual, $15/month monthly). It's polished, it learns from your corrections, it advertises itself as "4× faster than typing". It also runs entirely in their data centre — your audio leaves your machine on every dictation, and by default your transcripts are retained for "model improvement" until you flip the privacy toggle. Their context-awareness feature takes active-window screenshots every few seconds and uploads them to their servers.
Or you can install Handy — open-source, MIT-licensed, written in Rust, runs Whisper locally on your GPU. It's beautifully simple. It's also, by design, a hotkey wrapped around a model. It doesn't remember anything. You'll fix the same wrong word a thousand times.
There is a third option no one ships: local-first, GPU-accelerated, and learns from your edits. That's the empty quadrant.
That's where I built typwrtr.
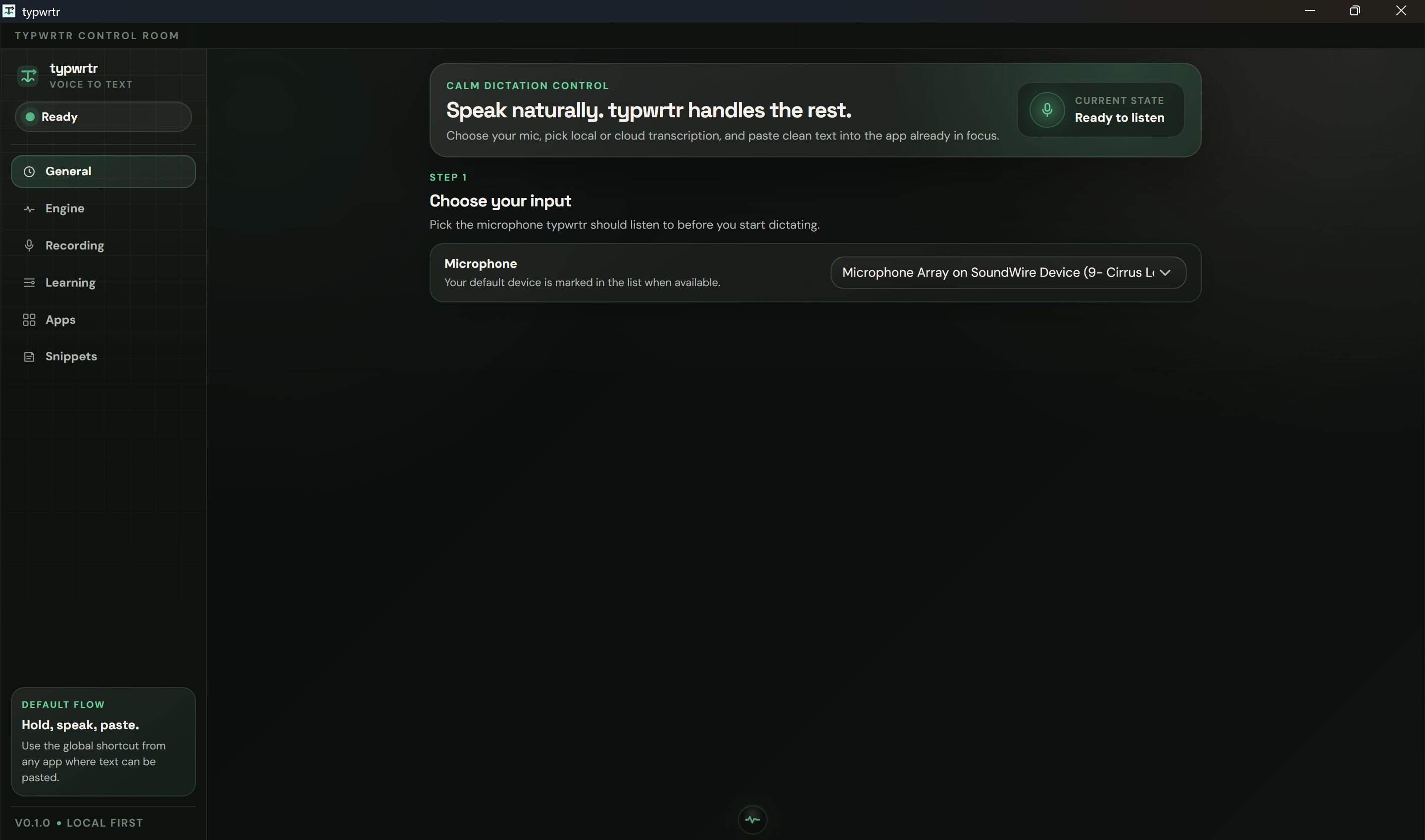
What's actually inside
The pipeline is three stages, in-process:
Capture. Push-to-talk hotkey, audio resampled to 16 kHz mono. Five-millisecond overhead before anything else runs.
Transcribe. Audio goes into whisper-rs 0.16, which links whisper.cpp natively with CUDA on Windows / Linux and Metal on macOS. The model is large-v3-turbo, an OpenAI Whisper variant. On an RTX 5070 Laptop, a 5-second utterance decodes in ~80 ms warm. (Whisper's 2022 paper is still worth reading; the model holds up extraordinarily well.)
Post-process and paste. Cleanup, replacement table, voice commands, postprocess mode (markdown / plain / code), deterministic scrub, then paste via OS-native synthesised keystroke — CGEvent on macOS, enigo on Windows.
End-to-end: ~150 ms warm, hotkey-release to text-on-screen. No network. No cold-start variance. No "your call could not be completed."
The whole thing is a Tauri app. Rust core, web frontend. Single static binary per OS.
The wedge: it learns
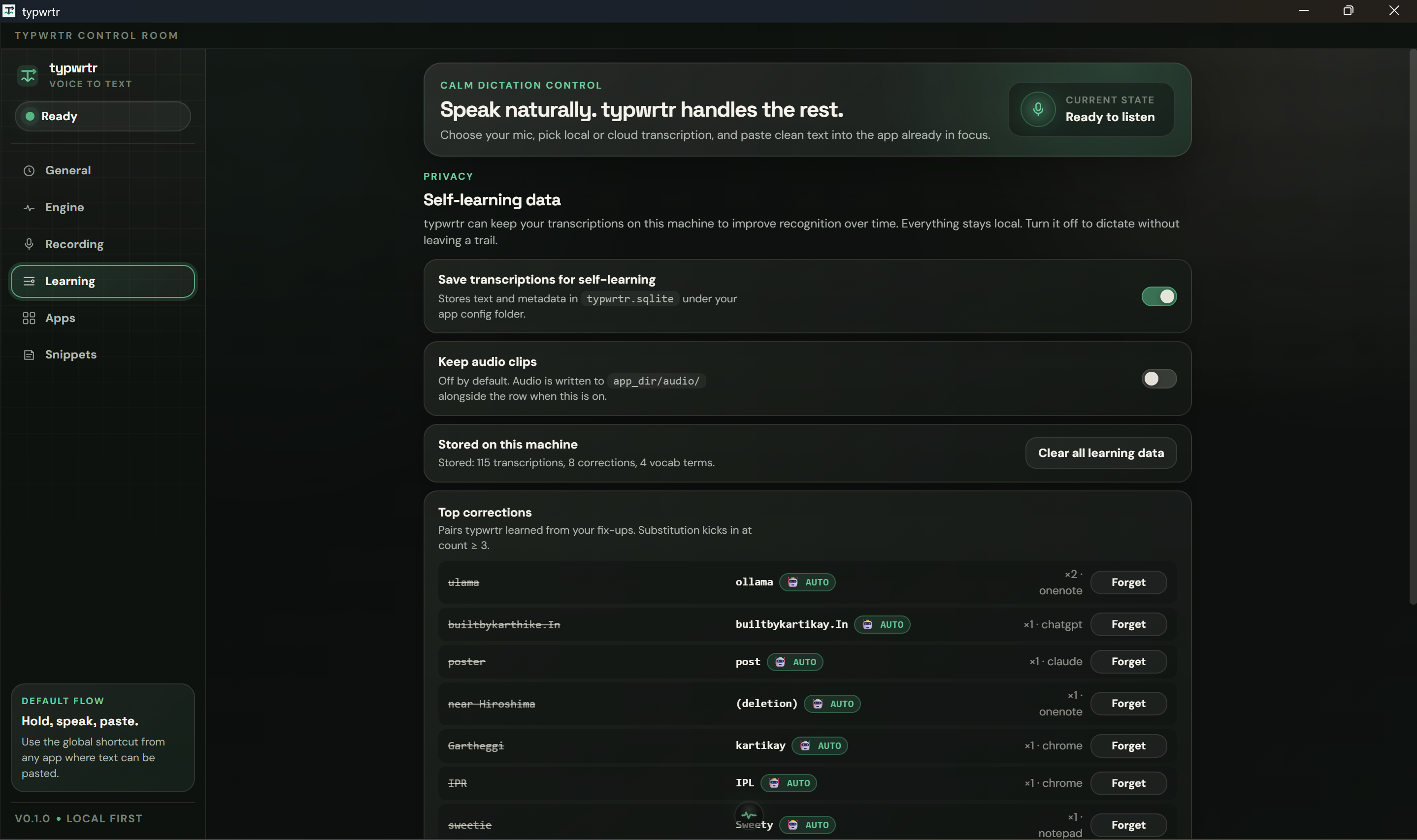
This is the part nobody else does.
After every paste, a background watcher polls the field that just received the text. It uses the platform accessibility APIs — UI Automation on Windows, NSAccessibility on macOS, AT-SPI2 on Linux — to read what's actually in the focused widget. (No screenshots. No screen recording. The accessibility API tells the watcher exactly the string the user is editing, scoped to one focused field.)
When your edits stabilise — or you click into a different window — the watcher diffs what's currently there against what we pasted. The differences are pairs: (wrong, right). They land in a SQLite corrections table.
The replacement table fires pre-paste on the next dictation, at count ≥ 1 — one fix is enough. Tombstones make this safe: hit "Forget" on any row, and it stays gone. Every false positive is one click recoverable. (For the data layer I just used SQLite — local, portable, you can sqlite3 ~/.../typwrtr.sqlite whenever you want and inspect everything the app knows about you.)
There's a second, smaller table — vocabulary. Proper-noun-shaped tokens get promoted automatically. The top 20 per-app and top 10 global ones are appended to Whisper's initial_prompt on every dictation, biasing the next decode toward your jargon. Names of co-workers, library names, project codenames — Whisper learns them after one correction.
Wispr Flow has a "personal dictionary" that does something similar. The difference is theirs lives in their cloud, with their schema, in a database you can't read, audit, export, or take with you when you change tools. typwrtr's lives in <app_dir>/typwrtr.sqlite. It's yours. Always.
The Karpathy-shaped roadmap item
The next phase is something Andrej Karpathy has been talking about for years: the future of personal AI is not bigger models, it's small models trained on your own data, in your own loop.
The roadmap calls for a trigram language model — Karpathy-flavoured, in the most literal sense — trained nightly on the user's own corrections. It rescores Whisper's top-k beams. Cheaper than a neural rescorer, falsifiable via held-out eval. If WER (word error rate) doesn't drop on real corpora, the feature ships disabled. If it drops 5%, we have a story.
The discipline is the kill switch. Building a feature and instrumenting it to disable itself if the data doesn't support it — that's not how the cloud incumbents work, because they'd rather ship and let usage data decide later. We do the opposite: ship behind a feature flag with a measurable goal.
Privacy, in concrete terms
This is the slide I show compliance teams.
What typwrtr sends to the network on a default install: nothing.
Audio is never transmitted. Optional retention to
<app_dir>/audio/, off by default.Transcripts: local SQLite. Toggle off and the recorder runs end-to-end without writing.
Post-processing is deterministic Rust passes inside the recorder. No daemon. No cloud LLM. No API keys to manage.
Clipboard is snapshotted before every paste and restored ~120 ms later. Dictation never silently overwrites what the user had copied.
Screenshots are never captured. No accessibility-tree scraping outside the focused field.
For comparison, Wispr Flow's default install sends audio to the cloud on every dictation, retains transcripts, and captures active-window screenshots every few seconds. That's not a critique of their product — it's how they implement context-awareness — but it disqualifies the architecture from a meaningful slice of the regulated market: healthcare, finance, government contracting, anything covered by a SOC 2 vendor review. typwrtr's "no audio leaves the machine" is a one-line answer to a security questionnaire.
Cost, in actual money
100 seats × 1 year of Wispr Flow at $12/month annual = $14,400.
1,000 seats × 1 year = $144,000.
100 or 1,000 seats × 1 year of typwrtr = $0. There's no per-transcription cost to pass on, because the model runs on the user's machine.
A few small flourishes
Per-app profiles. Every focused app gets a five-axis profile: vocabulary prompt, postprocess mode, code identifier case (snake_case / camelCase / kebab-case), preferred Whisper model, and a learning gate. The killer one is the gate — disable per-app for sensitive contexts (HR tools, password managers). Wispr Flow has tone-per-app; typwrtr has a switch the legal team can audit.
Phonetic matching. The replacement table uses the Metaphone phonetic algorithm for fuzzy fallback. If Whisper hears chiropractor and you've previously taught it chyropracter, the phonetic match catches the variant.
Voice commands that compose with snippets. You can dictate code mode my new function into VS Code and it pastes myNewFunction, because the IDE profile is set to camelCase and the voice command activated code mode in the same utterance. That's the kind of stacking the cloud architecture rules out.
Why this wins
Cloud dictation tools optimise for their flywheel: more usage → more training data → better models → more usage.
typwrtr optimises for yours: more usage → more corrections → better personal vocabulary → fewer corrections.
Theirs gets better for everyone, slowly. Mine gets better for you, immediately, in a way that's fully observable, fully reversible, and never leaves your machine.
That's the strategic difference, and it's the reason I think the local-first wedge in voice is real.
Try it
Open the typwrtr Control Room.
It's a Tauri app. It runs on Windows, macOS, and Linux. It is MIT-licensed. The data layer is yours, the model runs on your hardware, the source will be auditable, and the price is zero.
If you've been quietly paying for cloud dictation, give it a week. The first time it auto-corrects a name you only ever typed once before — without you having to tell it to — you'll feel the difference.
References & further reading
Handy (cjpais/Handy) — the open-source local Whisper baseline
Aho-Corasick algorithm · Metaphone · n-gram language model · Voice activity detection
Stay in the loop
Get notified when I publish new articles and projects.